Executive Summary:
My team partner (Rachel Kogan, a NYC Data Science Academy bootcamp classmate) and I filtered the Wikipedia English corpus down to bags of words using pySpark and trained machine learning models to detect bias (point of view tags) on TF-IDF data with nearly 90% accuracy.
Motivations:
The tide of news about fake news has reached a crescendo, and not many feasible solutions have been proposed for controlling the spread of biased information. The push for Facebook and other large social media sites on which most fake news seems to promulgate to manually editorialize their content is certainly infeasible for one. This problem seems ripe for machine learning approaches, specifically Natural Language Processing, so we set out to develop models that could detect bias in a large textual corpus. Due to its ease of access and pre-labeled content, we trained our models on the English Wikipedia corpus.
Wikipedia is one of the topmost visited websites in the English-speaking world and serves as a first go-to when looking for a quick overview on almost any topic. It’s surprisingly accurate and reliable given its anyone-can-edit ideology and site structure (roughly as reliable as the Encyclopedia Britannica according to a 2005 Nature study). Bots and users alike peruse the site for vandalism and other problematic edits, marking certain sentences, paragraphs, and entire articles as having a problem from a specific set of pre-defined tags. Fortunately for us, POV, or point of view (implying non-neutral point of view) is one such tag. There are several thousand articles in the English language Wikipedia with current POV tags, which provided a substantial enough body of data with which to train a bias detector. We downloaded the entire current-version (as of May 2017) English Wikipedia corpus in XML and stored it in the cloud using Amazon’s EC2 and S3 services. After separating the massive (~64GB) textual dataset into separate pages by the embedded XML page tags, we were able to filter the pages down to the usable articles (removing redirect pages, talk and other user pages, and simple list pages). The POV tags within each page’s text follow a replicable format (“{{POV … }}”), allowing for a regex-like filtering of the total articles down to just the articles with POV issues, and furthermore, articles for which the entire body of text is tagged as having POV issues (as opposed to just a paragraph or single line) also show a replicable special POV tag located in the header of the text, making filtering out articles with only very minor POV issues simple.
We then sampled from the rest of the corpus (presumably without POV issues) to generate training and test data sets with roughly equal proportions of non-neutral and relatively neutral articles. The XML markdown-style documents were then parsed with a set of regular expressions to generate a simple bag of words for each article (thereby removing all tags, including those that mark the article as having POV issues). We tokenized the bags of words and removed stop-words, followed by generating TF-IDF values for each unique term in each document (Term Frequency Inverse Document Frequency is a canonical way to calibrate simple bag of words term counts into relative term importances by adjusting by the rarity of each term across the entire corpus).
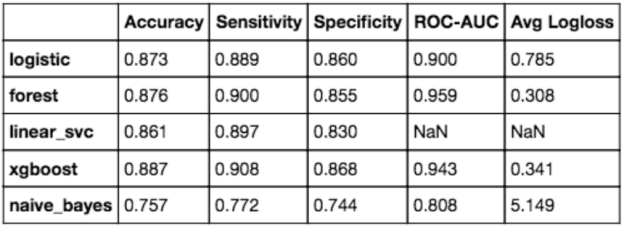
We trained many kinds of models to analyze which may be best at detecting bias in Wikipedia articles (and, by extension, in other sources of textual data as well). Among the best performers were logistic regression, random forest, and XGBoost (see metrics below).
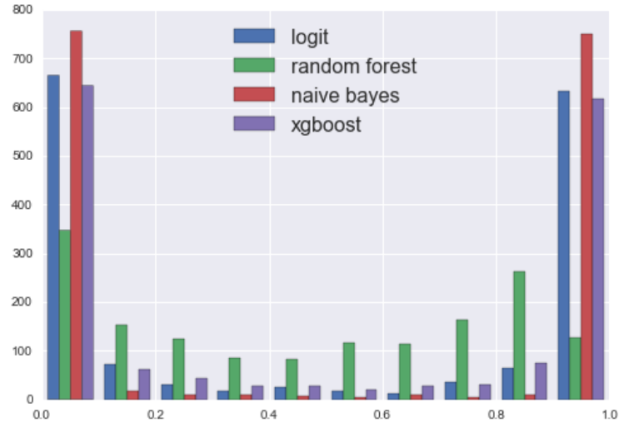
Additionally, we found that our models were fairly confident in their predictions, giving further credence to the idea that something as complicated as bias can be well handled by NLP and machine learning methods (x-axis is predicted probability, and y-axis is the number of such observations):
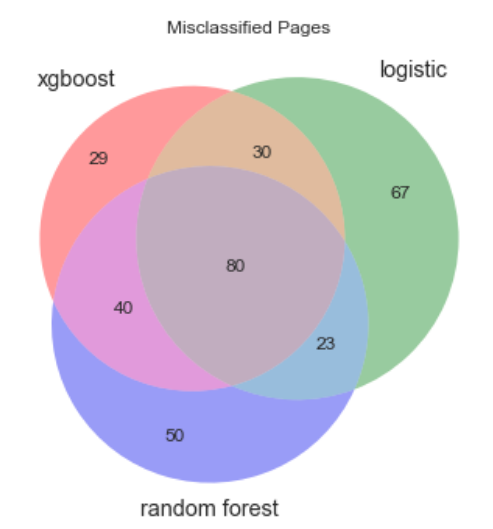
We further investigated correlations in misclassification between these models to see if an ensembled approach would significantly improve our results. However, high correlations between our models limited the extent to which we could improve our overall misclassification rate through ensembling. As you can see below, any majority-voting metric would have misclassified at nearly the same rate.