
Links to code on Github: mnist_utils.py and mnist_features.py
Executive Summary:
I’ve created a set of functions that can pre-identify some features in the MNIST data set that one would normally imagine a first or second hidden layer handling. Mainly, it can identify (with some limited success) distinct straight line segments. Further steps will include feeding this information into a neural network to assess whether it improves classification accuracy or not, and improving the feature detection as well.
Motivations:
Neural networks, especially those of the convolutional or capsule variety, have an astounding ability to recognize and process images. However, they come with one major drawback: the reliance on an enormous volume of data for training. The amount of data and training they require is often a barrier to developing a competent network at a sufficiently difficult task (in terms of access to enough data or access to enough computing power). This need is beyond that of other machine learning approaches, and well beyond what seems necessary for learning in their distant biological cousins. For instance, I let you study one example of one Chinese character closely for some time (a few minutes should suffice), even with no prior knowledge of Chinese, you would be able to discern it against other Chinese characters. Furthermore, you would nearly as easily recognize it in scale- and rotationally variant forms. As deeper neural networks (which have traditionally been the direction for improving computer vision performance) explore increasingly astronomic possibility spaces (in which it’s hard to imagine converging on a workable solution), I can’t help but wonder if there are any sensible hard-coded features that are worth adding into neural networks to allow shallower neural networks (and accordingly less data and less processing) to achieve similar performance, as if by acting as a replacement solution for one or more lower layers. Such an approach would also help to make the resulting neural network systems less of a black box. Below, as an ongoing project, I’ve catalogued some explorations into possible features that may aid in classification of the MNIST handwritten digits, with the purpose of further improving my understanding of image techniques and as a means to explore neural networks.
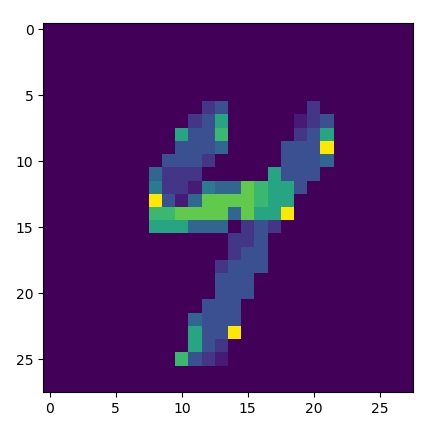
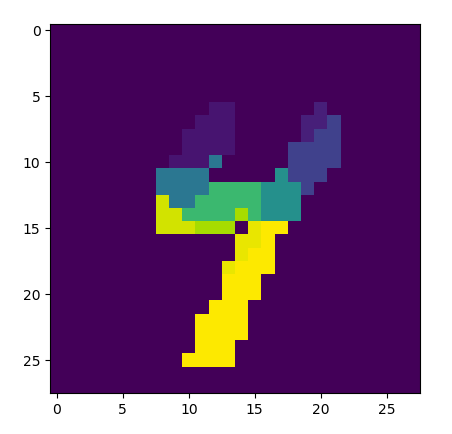
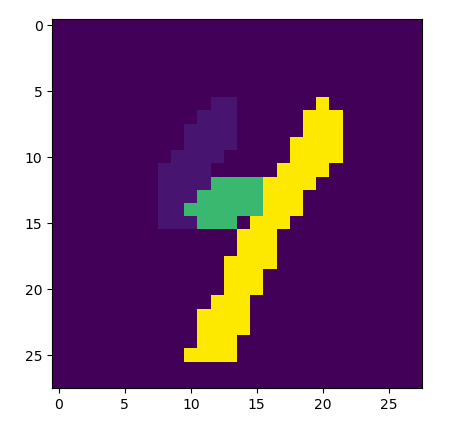
The feature detection works by calculating basic image gradients at each pixel, arbitrarily assigning a direction orthogonal to the gradient at each pixel (always a ninety-degree rotation in the same direction), clustering the pixels into discrete groups based on pixel alignment with their neighbors, and systematically flipping the polarity of their directions until optimally “laminar” flow is achieved throughout the whole system (until each pixel group is most similarly aligned with its neighbor groups). These groups, when further clustered by similarity in alignment, outline distinct line segments.
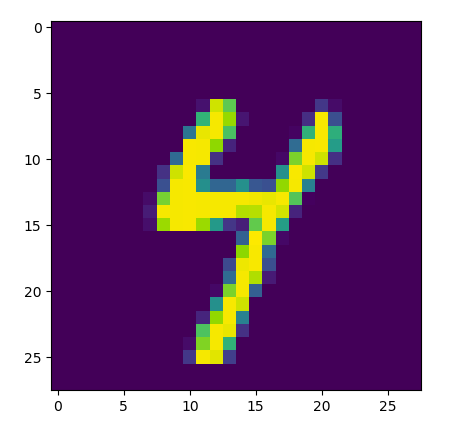
Original image:
Angle based on gradient direction:
Clustered into small groups:
Joined into segments:
Below are two examples for each digit. Results are unfortunately still inconsistent for curvy digits (0, 2, 3, 5, 6, 8, 9), though fairly consistent for straighter-line digits (1, 4, and 7).




















